
Time travelling with AWS Timestream: Simulate data in the future
No, this isn’t the next movie title from Back to the Future, although it would be pretty cool if they made another film. In this post, I’ll share a project where I’ve used AWS Timestream to store both real-time and historical data. We’ll explore how it can be used to replay historical data in the present or even predict future scenarios.
What is AWS Timestream
To provide a brief overview of Timestream, it’s an AWS serverless service that allows you to ingest and store time-series data for subsequent analytical queries. Think of it as a managed version of InfluxDB. As of this writing AWS now also offers InfluxDB as a managed service (not serverless though).
Background
In this project IoT data were collected and ingested into AWS Timestream using AWS IoT Core rules. The data would then be consumed by microservices implemented as AWS Lambda for further analysis. Finally the data would then be visualized using AWS Managed Grafana and monitored.
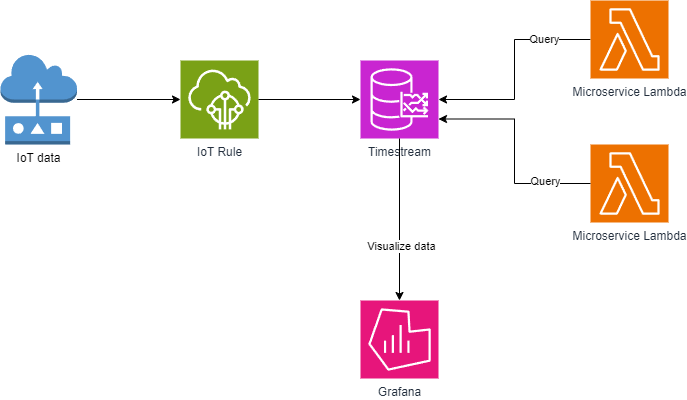
E2E test
An automated end-to-end (E2E) test ensures that the entire system functions as expected and can be run on-demand. The test would be responsible for ingesting live data through the system, and the idempotent operation ensures that the system’s success can be reliably verified.
To achieve this, we’ve established an additional Timestream database for ingesting historical data for various scenarios, and during end-to-end testing, the microservices seamlessly transition to utilizing the new Timestream.
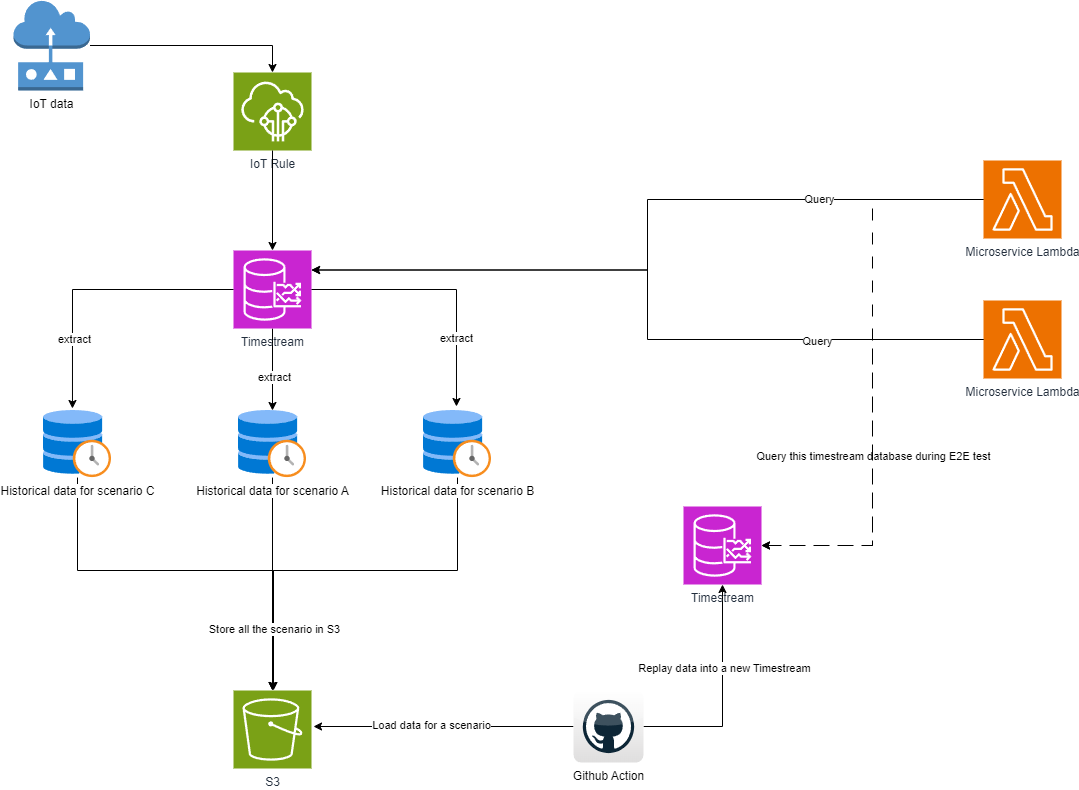
In this manner, the original Timestream database can continue to function normally, receiving live data without any contamination from simulated data.
Simulate Historical data in the future
To ensure that our system functions correctly after each new deployment, our end-to-end (E2E) tests should include regression tests. We need to simulate historical data by replaying it as if it were live data.
To prepare for the various scenarios we wanted to test, we need to extract historical data for each scenario into an S3 bucket from which we could replay the data (see Figure 2).
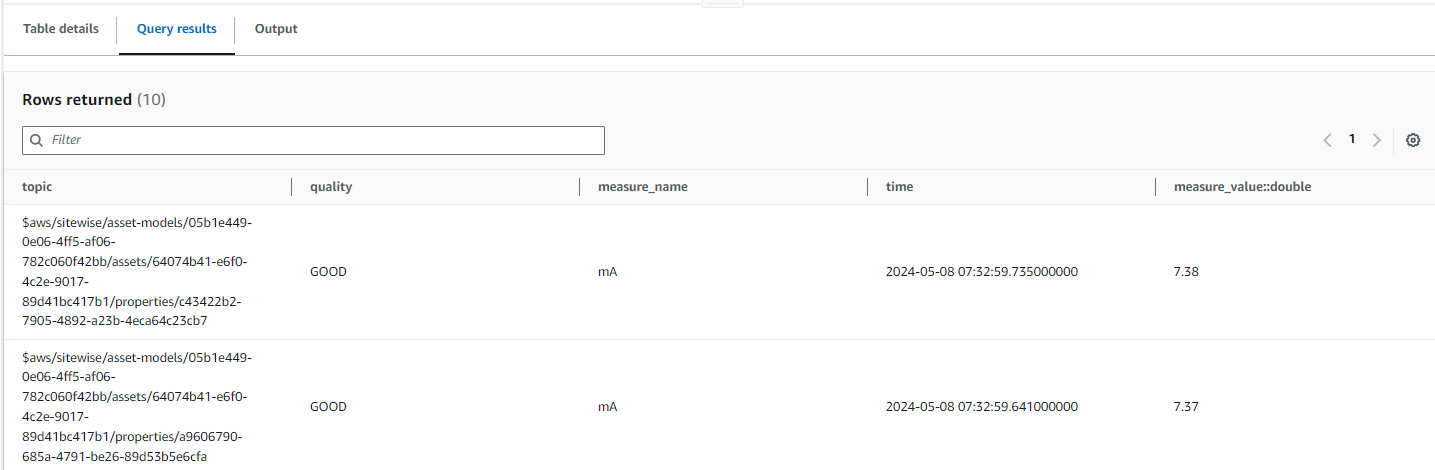
Below is a sample query of how our data looked like in Timestream:
select * from "iot"."data" where time between ago(15m) and now() order by time desc limit 10
Output:
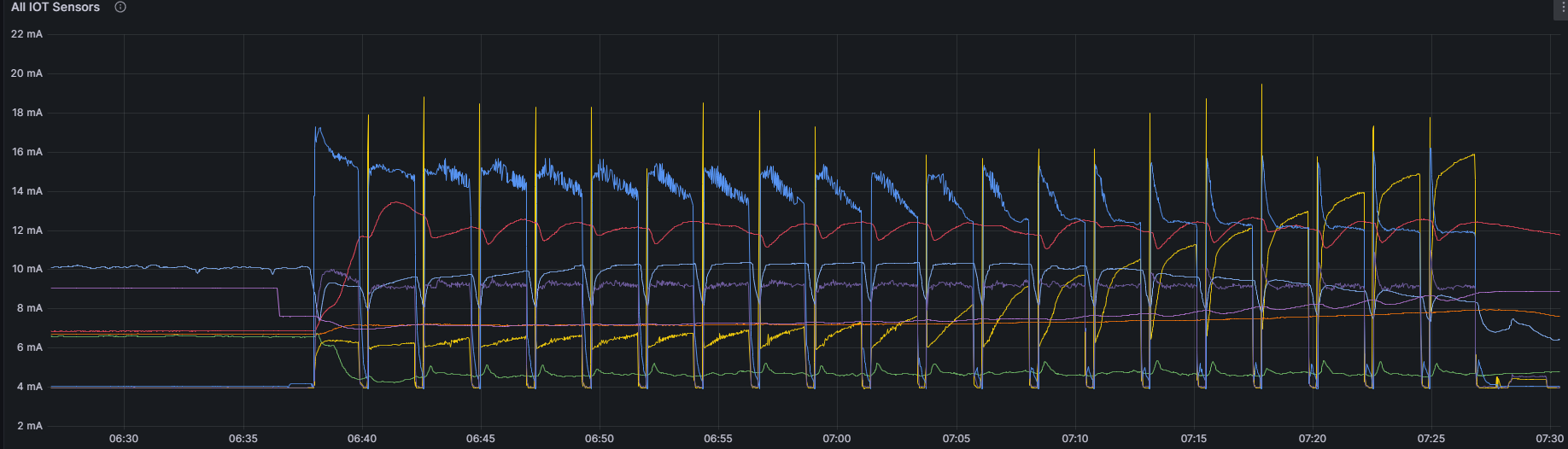
In Grafana we can visualize the data:
Prepare data
We identified the time range from which we wanted to use historical data and extracted that data into an S3 bucket using the UNLOAD function in Timestream.
UNLOAD (
SELECT
to_milliseconds(time - FIRST_VALUE(time) OVER (ORDER BY time)) AS offset,
*,
measure_value::double as value
FROM "iot"."data"
WHERE time between TIMESTAMP '2024-02-01 05:33:50' and TIMESTAMP '2024-02-01 06:25:43' ORDER BY time
)
TO 's3://datasimulator/datasets/scenario_a/'
WITH (
format = 'CSV',
compression = 'NONE',
include_header = 'true'
)
The provided query describes an operation that extracts data from a Timestream database and stores it in an S3 bucket in CSV format. Let’s break it down:
- UNLOAD Query: The term “UNLOAD” typically refers to a command or operation in a database system that exports data from a table or database. In this case, it’s used to extract data from the Timestream database.
- Period Specified: The query includes a time range or period (start and end timestamps) within which the data should be extracted. This ensures that only relevant data is included.
- Offset: This field will hold the milliseconds offset from the first row. Each row will indicate the milliseconds offset from that initial point. Later, when you replay all the data into the present or future, this offset will be useful.
- S3 Bucket: The extracted data is being stored in an S3 bucket.
- CSV Format: The data is exported in Comma-Separated Values (CSV) format. CSV files are commonly used for tabular data and can be easily imported into other tools or databases. The data is not compressed during the extraction process. This means that the resulting CSV files will be larger in size but can be directly read by applications without decompression.
The output would look like the following:
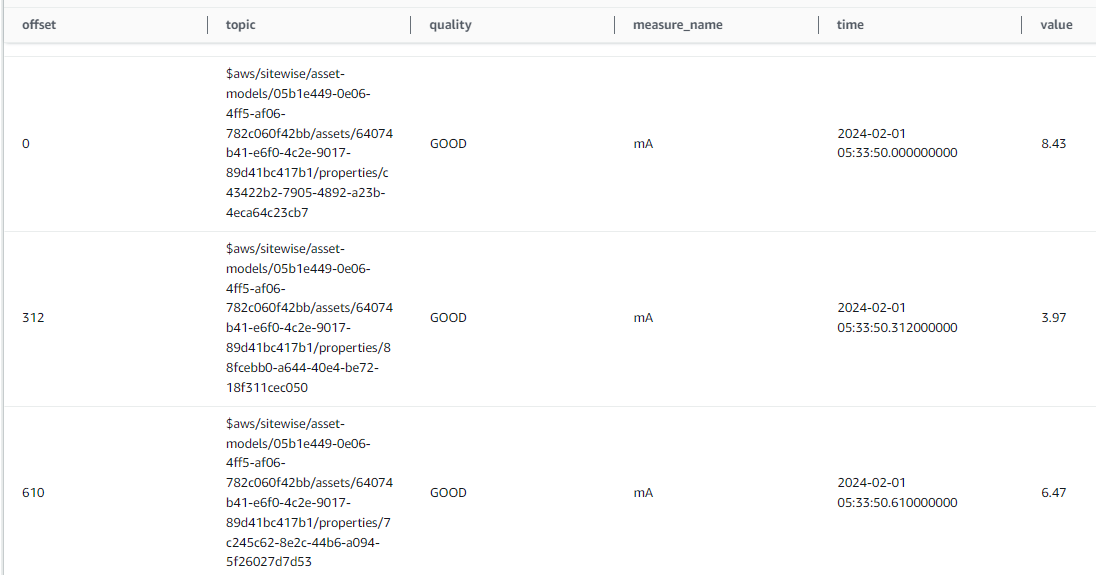
The data that gets stored in S3 have the following structure:
As depicted in Figure 6, the UNLOAD function generates two JSON files and a folder named results/. All the CSV files are then organized within the results/ folder, as illustrated in Figure 7.
One of the JSON file ending with _manifest.json file holds essential information about all the CSV files related to the extraction process. It acts as a reference or guide, providing details such as file names, paths, and metadata associated with each extracted CSV file. This manifest simplifies data management and ensures that all relevant files are properly organized and accounted for.
Expand/Collapse Code
{
"result_files": [
{
"url": "s3://datasimulator/datasets/scenario_a/results/AEDQCANSCVPS5T4SPHMGMGGGZAMDCKY6GXPXPXCTGGUEVSASDKSWVGI663IF2FY_0341598655_tx8j75GD9FXRv1Wz.csv",
"file_metadata": {
"content_length_in_bytes": 1277775,
"row_count": 4088
}
},
{
"url": "s3://datasimulator/datasets/scenario_a/results/AEDQCANSCVPS5T4SPHMGMGGGZAMDCKY6GXPXPXCTGGUEVSASDKSWVGI663IF2FY_0341598655_JS6JM9sYIr5ORALE.csv",
"file_metadata": {
"content_length_in_bytes": 2360503,
"row_count": 7538
}
}
],
"query_metadata": {
"total_content_length_in_bytes": 7793122,
"total_row_count": 24906,
"result_format": "CSV",
"result_version": "Amazon Timestream version 1.0.0"
},
"author": {
"name": "Amazon Timestream",
"manifest_file_version": "1.0"
}
}
When replaying the data the manifest file would be read to find all the CSV files to load.
Replay data
The data replay process is handled by a custom TypeScript script, which is executed via a GitHub Action. The script is responsible for retrieving historical data from S3 and ingesting it into a new Timestream database. The timestamps for this data are set to the present time and slightly into the future.
Let’s look at how this is achieved.
The script retrieves the manifest.json file from Amazon S3, as previously discussed. By analyzing the manifest, the script identifies and locates the specific CSV files needed for the replay.
We aim to ingest as much data as possible into the new Timestream database while ensuring maximum speed. However, Timestream imposes the following constraints:
- Max 15 minutes into the future
- Max 100 records per write
What about the batch load functionality of Timestream? The challenge with using the batch load function is that it still adheres to the 15-minute constraint. Additionally, we wouldn’t have fine-grained control over how much data we can ingest if we rely solely on this method.
Our approach involved breaking down the data into 15-minute chunks extending into the future. For efficient ingestion, we then performed batch writes, handling 100 records per write. To safeguard against data loss due to potential throttling by the Timestream API, we implemented exponential retries when inserting records.
Calculate new timestamps using offset
To ensure that our historical data receives the correct timestamps when replayed into the present time, we utilized the offset field that we had calculated during the extraction. By adding this offset to the present time, we can accurately replay historical data into any future date while maintaining correct data timestamps.
Final thoughts
AWS Timestream is an excellent database for storing time-series data, and its SQL syntax simplifies analytical queries. While data ingestion into Timestream is straightforward, there are limitations when handling timestamps in the future. We encountered these limitations in this project where we needed to simulate live data and ensure efficient simulation performance.
Furthermore, Timestream does not allow the deletion of existing records, which complicates data cleanup. Instead, the only option is to perform a complete table deletion.