
Dynamic partitioning in AWS Athena using Projection
In this blog post, I want to discuss a project I’ve been working on for a customer, which involves optimizing Athena queries for a large amount of IoT data stored in S3.
Storing IoT Data in AWS S3
In this project, we faced the challenge of efficiently storing and analyzing a vast amount of IoT data generated by machine sensors. Our solution involved streaming the IoT data directly from diverse sensors to AWS S3, providing a scalable and cost-effective storage solution in the AWS cloud.

We opted for AWS Athena to empower data scientists with query capabilities, as it eliminates the need for additional complex infrastructure setup or management.
Partition! Partition!
Understanding partitioning and its significance is crucial for optimizing data storage and enhancing query performance.
S3 partitions
First, let’s review the S3 partitioning strategy we’ve implemented, designed to facilitate efficient querying of data based on the patterns identified by the data scientists.
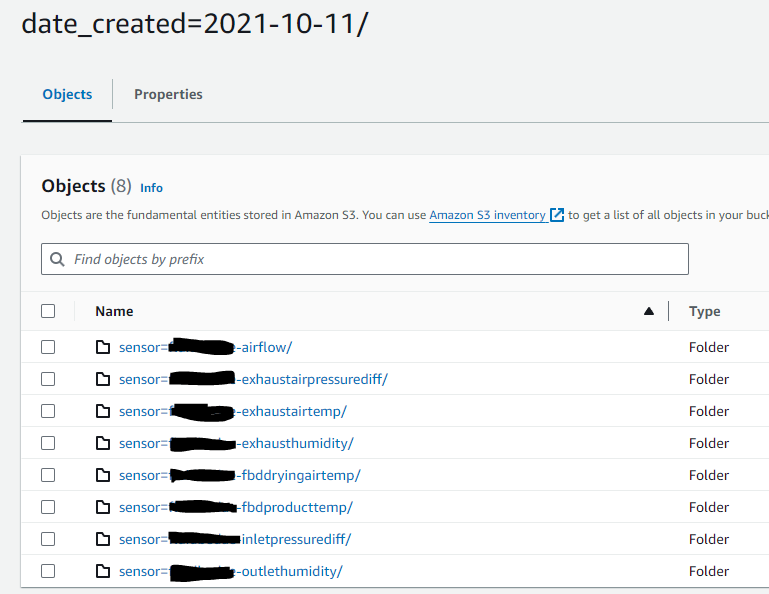
The data scientists usually analyze the sensor data by date and sensor type and so it requires us to partition the data according to the following pattern:

Then by sensor type
For the discerning reader, you might be wondering about timestamps. Why aren’t we also partitioning the date by timestamp?
Given that all IoT data is timeseries, a significant volume streams in every second, even millisecond. Partitioning the data at such granular levels—seconds, milliseconds, or even minutes—would excessively fragment the partition table and incur additional storage costs without commensurate improvements in query performance. Furthermore, our data scientists typically analyze data on a daily basis rather than filtering at the level of seconds or milliseconds.
Finally the data format is stored in Parquet with snappy compression
Athena query optimization
Now that we have the underlying data structure partioned and stored in S3 let’s understand how we can efficiently query the data in a performant way using AWS Athena.
Our data scientists usually performs analysis on the IoT data using similar query patterns as the followings:
-- get all sensor data between two dates
SELECT * from iot
WHERE date_created BETWEEN DATE '2021-01-01' and DATE '2021-01-02'
-- get specific sensor for a specific date
SELECT * from iot
WHERE date_created = DATE '2021-01-01'
AND sensor = 'sensorA'
Where the results can look like this

Now the above queries will run quite fast due to the partitions we have created for our S3 bucket where we have added partitions for filtering on date_created and sensor.
We can take a look at the query stats to see how the Athena query plan looks
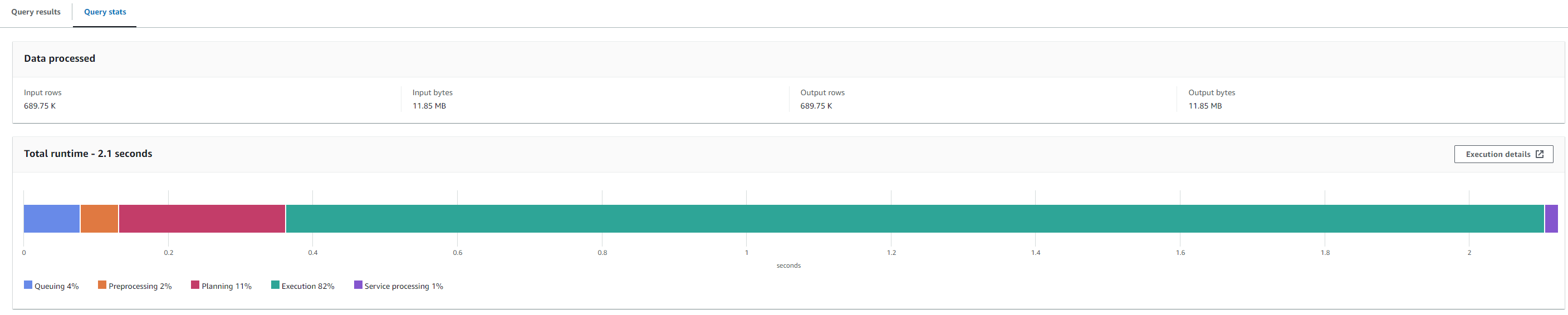
While the overall performance of Athena is quite decent, I’m concerned about the 11% spent on the planning phase. What exactly is causing this delay?
Athena employs a concept known as Partition Pruning during the planning phase. Here, Athena collects metadata and ‘prunes’ it down to only the partitions relevant to the query. This involves calling the API GetPartitions to the AWS Glue Data Catalog before performing partition pruning.
So can we reduce the time spent on retrieving metadata from AWS Glue Data Catalog and pruning the partitions? The answer is yes, but before I show you how let’s first explain a bit about the AWS Glue Data Catalog and how it stores partitions.
How partitions are managed by AWS Glue Data Catalog
The Athena query leverages the AWS Glue Data Catalog to store metadata about partitions and the location of S3 files for each partition.
Take a look at the Glue table that is used by the Athena query to find and locate the partitions for IoT data in S3:
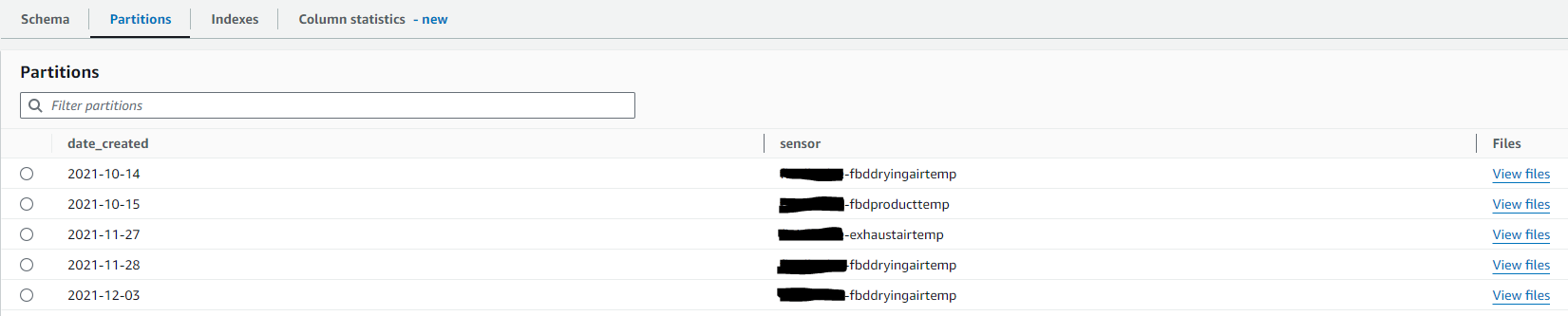
As depicted in the above image, the Glue table contains two partitions: date_created and sensor, which point to the location where the actual data is stored in S3.
Now, suppose new data arrives for the next day; we’ll need to update the partitions in the Glue table with information about the new data.
There are several ways of updating the metadata in the Glue Data Catalog:
- Utilizing an AWS Glue Crawler on a scheduled basis to crawl S3 and update the data catalog
- Using the Athena
MSCK REPAIR TABLEcommand. This needs to be called on a schedule as well.
Opting for a scheduled Glue Crawler is certainly preferable to manually invoking MSCK REPAIR TABLE on a schedule, yet it still necessitates additional setup and maintenance.
But is there another way? Yes, Partition Projection.
Partition Projection
You can use partition projection in Athena to speed up query processing of highly partitioned tables and automate partition management. So let’s take a look at how this helps solve our issue with partition management as well as speed up our Athena query.
To enable projection partition we need to add the following properties to our Glue Table see figure 8.
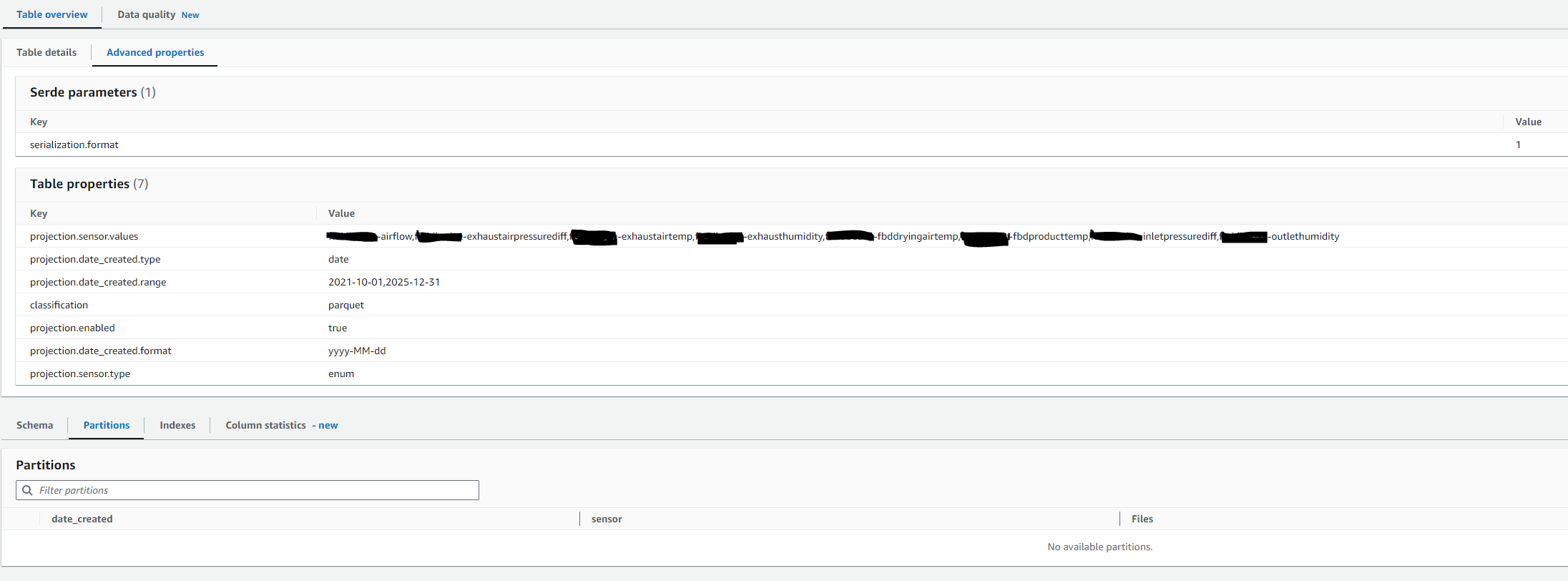
The key properties are as follows:
- projection.enabled = true
- projection.date_created.type = date
- projection.date_created.range = 2021-10-01,2025-12-31
- projection.date_created.format = yyy-MM-dd
- projection.sensor.type = enum
- projection.sensor.values = <list of values separated by comma>
Additionally, it’s important to note that the Glue table no longer stores metadata about the partitions and their location in S3. Instead, this information will be determined from the specified properties.
Let’s go over the properties and explain what it means.
projection.enabled - this must be set to true to enable partition projection
projection.date_created.type - here we specify the date_created column should be a partition column of type date
projection.date_created.range - here we specify the date range for the date_created partition column. This will essentially allow Athena to project and determine all the values for the date_created partition without the need to recrawl and update partitions whenever new data arrives.
projection.date_created.format - here we specify the format of the date_created partition column
projection.sensor.type - here we specify the sensor column should be a partition column of type enum
projection.sensor.values - this is the list of all possible enumeration values for the sensor column
By specifying the structure of the partition columns, we enable Athena to calculate and locate the S3 files to scan during a query. This approach reduces the need for partition management, eliminating the requirement for a Glue Crawler to update partitions with new data. Additionally, it allows Athena to bypass calls to the API GetPartitions during the planning phase.
Let’s take a look at how the Athena query performs once we have enabled partition projection.
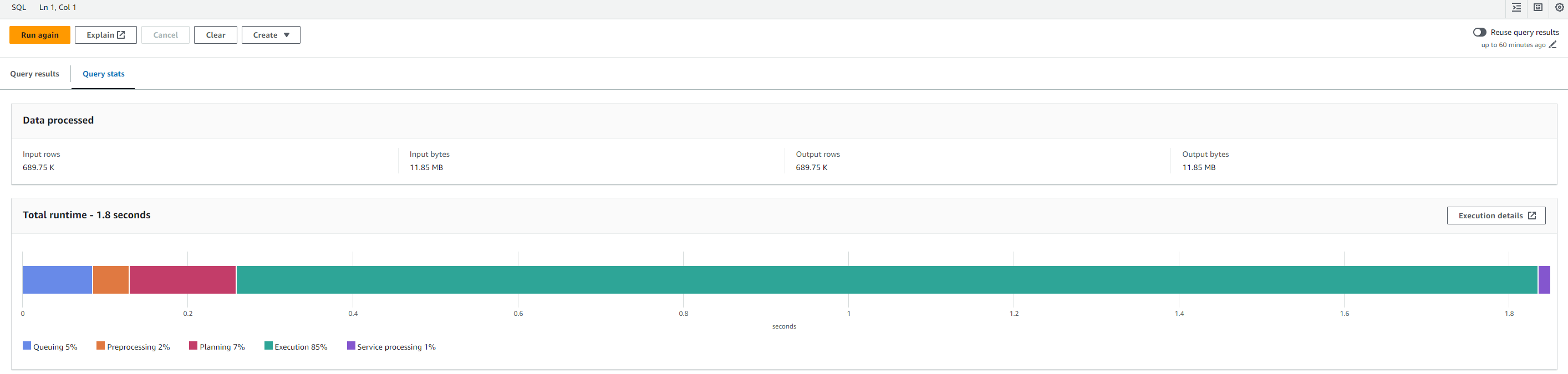
The planning phase now takes about 7%, down from the previous 11%, and the overall query time has decreased to 1.8 seconds from 2.1 seconds.
Conclusion
In conclusion, we’ve successfully enhanced the Athena query while simultaneously reducing the overhead of updating partitions through Athena’s Partition Projection. While it may not always be applicable depending on specific use cases, for our purposes, it significantly streamlines setup and enhances performance.